
















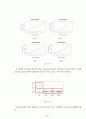
















-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
해당 자료는 7페이지 까지만 미리보기를 제공합니다.
7페이지 이후부터 다운로드 후 확인할 수 있습니다.
7페이지 이후부터 다운로드 후 확인할 수 있습니다.




목차
1. 초록
2. 서론
(1) 데이터분석의 목적과 계획
(2) 사용자료 및 분석방법
3. 본론
(1) 분산분석 : 1960~2010년 기대수명 증가율 비교
(2) 유의성 검정 : 분산분석에 영향을 주는 집단 구분 및 추가분석
(3) 독립성검정 :성별과 질병과의 관계
(4) 다중회귀분석 : 다양한 요인에 의한 기대수명 예측
4. 결론
2. 서론
(1) 데이터분석의 목적과 계획
(2) 사용자료 및 분석방법
3. 본론
(1) 분산분석 : 1960~2010년 기대수명 증가율 비교
(2) 유의성 검정 : 분산분석에 영향을 주는 집단 구분 및 추가분석
(3) 독립성검정 :성별과 질병과의 관계
(4) 다중회귀분석 : 다양한 요인에 의한 기대수명 예측
4. 결론
본문내용
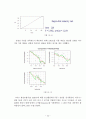
렴점을 확인해보았다. 최대의 기대수명을 알아보기 위해서 각(each) 독립변수(independent)들의 최소값을 모형에 대입하여 결과를 산출하였다. 그 결과 그림 ( )와 같은 결론이 도출되었다. 이 모형에 의해 설명되는 기대수명의 수렴 지점은 86.04세이다.
그림 (5-10)
본 논문에서는 기대수명에 대한 다양한 분석을 통하여 기대수명의 증가율을 비교하여 앞으로 증가율의 방향을 예측하고 차이가 나는 이유를 설명하였다. 또한 회귀식을 도출하여 앞으로 기대수명에 영향을 미치는 요인들을 통해 대략적인 기대수명을 예측 할 수 있다. 그리고 요인들의 영향을 파악해 기대수명 상승을 위한 중요한 자료로 쓰일 수 있을 것이라 판단된다.
반면 본 논문의 한계점으로써는 사용된 데이터의 양이 크지 않아 정규성이 낮고 다양하지 않은 변수의 생성으로 인해 실질적으로 모형 개발에 선택된 파생변수 생성이 필요하다. 또 모형을 개발하는 데 있어 여러 가지 기법을 통해 최적의 모형을 선별해야 할 것이다.
본 논문은 기대수명 예측을 위한 분석으로 쓰였지만 우리사회의 큰 문제로 떠오른 고령화 문제를 대비하여 정년퇴직 나이나 연금문제에 관련한 정책사항 결정에 있어 미리 기대수명을 예측하여 대비함으로써 유용하게 사용하여 더 실효성 있는 선택에 영향을 줄 것이다.
참고문헌
- 김남순, (2014). 한국 여성의 전반적인 건강수준 차이 - 기대수명, 건강인식 및 활동제한 중심으로, 한국보건사회연구원, 통권 제210호, 6p.
- 한소연, (2012). 우리나라 지역별 건강수명과 관련요인, DBpia, 제 35권 제2호, p.229.
R-코딩
<분산분석>
#데이터 불러오기
x=read.csv("C:/R/ANOVA.csv",header=T)
#정규성 검정
shapiro.test(x$X67y)
shapiro.test(x$X78y)
shapiro.test(x$X89y)
shapiro.test(x$X90y)
library(car)
qqnorm(x$X67y)
qqline(x$X67y)
qqnorm(x$X78y)
qqline(x$X78y)
qqnorm(x$X89y)
qqline(x$X89y)
qqnorm(x$X90y)
qqline(x$X90y)
#분산분석
b.life=stack(x)
boxplot(values~ind,data=b.life)
life.aov=oneway.test(values~ind,data=b.life,var.equal=F)
pairwise.t.test(b.life$values,b.life$ind,pool.sd=F)
<유의성 검정>
#유의성 검정
t.test(x$X67y,x$X78y)
t.test(x$X67y,x$X90y)
t.test(x$X67y,x$X89y)
t.test(x$X78,x$X89y)
t.test(x$X78,x$X90y)
t.test(x$X89,x$X80y)
t.test(x$X78,x$X90y,alt='greater')
t.test(x$X89,x$X90y,alt='greater')
#데이터 불러오기
x1=read.csv("C:/R/M,F_life.csv",header=T)
D=x1[,5]
t.test(D)
life.city_a=c(81.58,78.96,79.59,79.76,79.94,80.27,79.05)
life.city_b=c(80.51,79.10,78.94,79.59,79.38,79.01,78.98,78.93,80.95)
t.test(life.city_a,life.city_b)
<독립성 검정>
#데이터 읽기, 카이제곱 검정
x=matrix(c(47768,6253,27098,12485,7278,28853,8751,30084,10005,3892),
nc=2)
(y=chisq.test(x))
<회귀분석>
#데이터
data.set=read.csv(file="C:/R/table3.csv", head=T, sep=',') ; data.set
#독립변수
life=cbind(data.set$life) ; life
cancer.1=cbind(data.set$암) ; cancer.1
micro.dust=cbind(data.set$미세먼지) ; micro.dust
saving.d=cbind(data.set$저축) ; saving.d
saving=cbind(data.set$실질저축) ;
shapiro.test(life) ; windows() ; plot(life, xlab="time", title="Test of normality")
#회귀모델
output_lm=lm(life~ log(micro.dust^2) + log(cancer.1)+ log(saving))
#요약통계량
summary(output_lm)
#산점도 행렬
library(lattice)
splom(~data.set, which="3")
#요약통계량
summary(output_lm)
회귀가정
# 오차항 등분산성
library(car)
ncvTest(output_lm)
windows() ; plot(output_lm, which=1) ; windows() ; plot(output_lm, which=3)
# 오차항 독립성
durbinWatsonTest(output_lm) ;
windows() ; el=residuals(output_lm) ; plot(el) ; abline(h=0, lty=2)
#오차항의 정규성
windows() ; par(mfrow=c(1,2))
qqPlot(output_lm) ; plot(output_lm, which=2)
shapiro.test(residuals(output_lm)) ;
#다중공선성
vif(output_lm)
#모델에 의해 설명되는 수렴기대수명
Life.Convergence=231.887-12.019*log(45.49^2)-1.507*log(700)-4.217*log(35705.44)
Life.Convergence
y
predicted.life=231.887-12.019*log(micro.dust^2)-1.507*log(cancer)-4.217*log(saving)
a.life
life
plot(predicted.life,life) ; t.test(predicted.life, life)
그림 (5-10)
본 논문에서는 기대수명에 대한 다양한 분석을 통하여 기대수명의 증가율을 비교하여 앞으로 증가율의 방향을 예측하고 차이가 나는 이유를 설명하였다. 또한 회귀식을 도출하여 앞으로 기대수명에 영향을 미치는 요인들을 통해 대략적인 기대수명을 예측 할 수 있다. 그리고 요인들의 영향을 파악해 기대수명 상승을 위한 중요한 자료로 쓰일 수 있을 것이라 판단된다.
반면 본 논문의 한계점으로써는 사용된 데이터의 양이 크지 않아 정규성이 낮고 다양하지 않은 변수의 생성으로 인해 실질적으로 모형 개발에 선택된 파생변수 생성이 필요하다. 또 모형을 개발하는 데 있어 여러 가지 기법을 통해 최적의 모형을 선별해야 할 것이다.
본 논문은 기대수명 예측을 위한 분석으로 쓰였지만 우리사회의 큰 문제로 떠오른 고령화 문제를 대비하여 정년퇴직 나이나 연금문제에 관련한 정책사항 결정에 있어 미리 기대수명을 예측하여 대비함으로써 유용하게 사용하여 더 실효성 있는 선택에 영향을 줄 것이다.
참고문헌
- 김남순, (2014). 한국 여성의 전반적인 건강수준 차이 - 기대수명, 건강인식 및 활동제한 중심으로, 한국보건사회연구원, 통권 제210호, 6p.
- 한소연, (2012). 우리나라 지역별 건강수명과 관련요인, DBpia, 제 35권 제2호, p.229.
R-코딩
<분산분석>
#데이터 불러오기
x=read.csv("C:/R/ANOVA.csv",header=T)
#정규성 검정
shapiro.test(x$X67y)
shapiro.test(x$X78y)
shapiro.test(x$X89y)
shapiro.test(x$X90y)
library(car)
qqnorm(x$X67y)
qqline(x$X67y)
qqnorm(x$X78y)
qqline(x$X78y)
qqnorm(x$X89y)
qqline(x$X89y)
qqnorm(x$X90y)
qqline(x$X90y)
#분산분석
b.life=stack(x)
boxplot(values~ind,data=b.life)
life.aov=oneway.test(values~ind,data=b.life,var.equal=F)
pairwise.t.test(b.life$values,b.life$ind,pool.sd=F)
<유의성 검정>
#유의성 검정
t.test(x$X67y,x$X78y)
t.test(x$X67y,x$X90y)
t.test(x$X67y,x$X89y)
t.test(x$X78,x$X89y)
t.test(x$X78,x$X90y)
t.test(x$X89,x$X80y)
t.test(x$X78,x$X90y,alt='greater')
t.test(x$X89,x$X90y,alt='greater')
#데이터 불러오기
x1=read.csv("C:/R/M,F_life.csv",header=T)
D=x1[,5]
t.test(D)
life.city_a=c(81.58,78.96,79.59,79.76,79.94,80.27,79.05)
life.city_b=c(80.51,79.10,78.94,79.59,79.38,79.01,78.98,78.93,80.95)
t.test(life.city_a,life.city_b)
<독립성 검정>
#데이터 읽기, 카이제곱 검정
x=matrix(c(47768,6253,27098,12485,7278,28853,8751,30084,10005,3892),
nc=2)
(y=chisq.test(x))
<회귀분석>
#데이터
data.set=read.csv(file="C:/R/table3.csv", head=T, sep=',') ; data.set
#독립변수
life=cbind(data.set$life) ; life
cancer.1=cbind(data.set$암) ; cancer.1
micro.dust=cbind(data.set$미세먼지) ; micro.dust
saving.d=cbind(data.set$저축) ; saving.d
saving=cbind(data.set$실질저축) ;
shapiro.test(life) ; windows() ; plot(life, xlab="time", title="Test of normality")
#회귀모델
output_lm=lm(life~ log(micro.dust^2) + log(cancer.1)+ log(saving))
#요약통계량
summary(output_lm)
#산점도 행렬
library(lattice)
splom(~data.set, which="3")
#요약통계량
summary(output_lm)
회귀가정
# 오차항 등분산성
library(car)
ncvTest(output_lm)
windows() ; plot(output_lm, which=1) ; windows() ; plot(output_lm, which=3)
# 오차항 독립성
durbinWatsonTest(output_lm) ;
windows() ; el=residuals(output_lm) ; plot(el) ; abline(h=0, lty=2)
#오차항의 정규성
windows() ; par(mfrow=c(1,2))
qqPlot(output_lm) ; plot(output_lm, which=2)
shapiro.test(residuals(output_lm)) ;
#다중공선성
vif(output_lm)
#모델에 의해 설명되는 수렴기대수명
Life.Convergence=231.887-12.019*log(45.49^2)-1.507*log(700)-4.217*log(35705.44)
Life.Convergence
y
predicted.life=231.887-12.019*log(micro.dust^2)-1.507*log(cancer)-4.217*log(saving)
a.life
life
plot(predicted.life,life) ; t.test(predicted.life, life)
추천자료
- 가격1,000원
- 페이지수22페이지
- 등록일2019.02.26
- 저작시기2015.9
- 파일형식한글(hwp)
- 자료번호#1082658

본 자료는 최근 2주간 다운받은 회원이 없습니다.




소개글